1. kafka 란?
apache kafka는 오픈 소스 분산 이벤트 스트리밍 플랫폼이다.
*데이터 파이프 라인 구성시, 주로 사용되는 오픈 소스로 대용량 실시간 로그 처리에 특화되어 많은 사람들이 사용하고 있다.
*데이터 파이프 라인: 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조를 가리킨다.
2. kafka의 특성
2.1. Publisher-Subscriber 모델
Publisher-Subscriber 모델은 중간에 데이터 큐를 두고 서로 간 독립적으로 데이터를 생산하고 소비한다.
이러한 구조를 통해, Publisher나 Subscriber에 장애가 생겨도, 독립적이기 때문에 안정적으로 데이터를 처리할 수 있다.
2.2. 고가용성 및 확장성 (High availablility and Scalability)
kafka는 cluster 구조로 데이터를 분산하여 저장한다.
따라서 하나의 broker에 장애가 생겨도 가용성이 높다.
또한 클러스터를 수평적으로 늘려 안정성 및 성능을 향상시키는 Scale-out이 가능하다.
2.3. 디스크 순차 저장 및 처리
메세지를 메모리 큐에 적재하는 기존 메세지 시스템과 달리 kafka는 메세지를 디스크에 순차적으로 저장한다.
따라서
서버에 장애가 나도 메세지가 디스크에 저장되어 안정성이 높고 순차적으로 저장되어 I/O작업이 줄어들어 성능이 좋아진다.
2.4. 분산 처리
kafka는 partition을 통해 여러개의 partition을 여러개의 서버에 분산시켜 나누어 처리할 수 있다.
3. kafka의 구조
3.1. Publisher-Subscriber 모델
Pub-Sub (발행-구독) 모델은 특정 시스템에 직접 메세지를 전달하는 시스템이 아니다.
publisher은 메세지를 *Topic을 통해서 분류하여 관리하고, receiver은 전달받기를 원하는 *Topic을 구독하여 메세지를 전달 받는다.
즉 *kafka cluster를 중심으로 producer가 push하고, consumer가 메세지를 pull하는 구조이다.
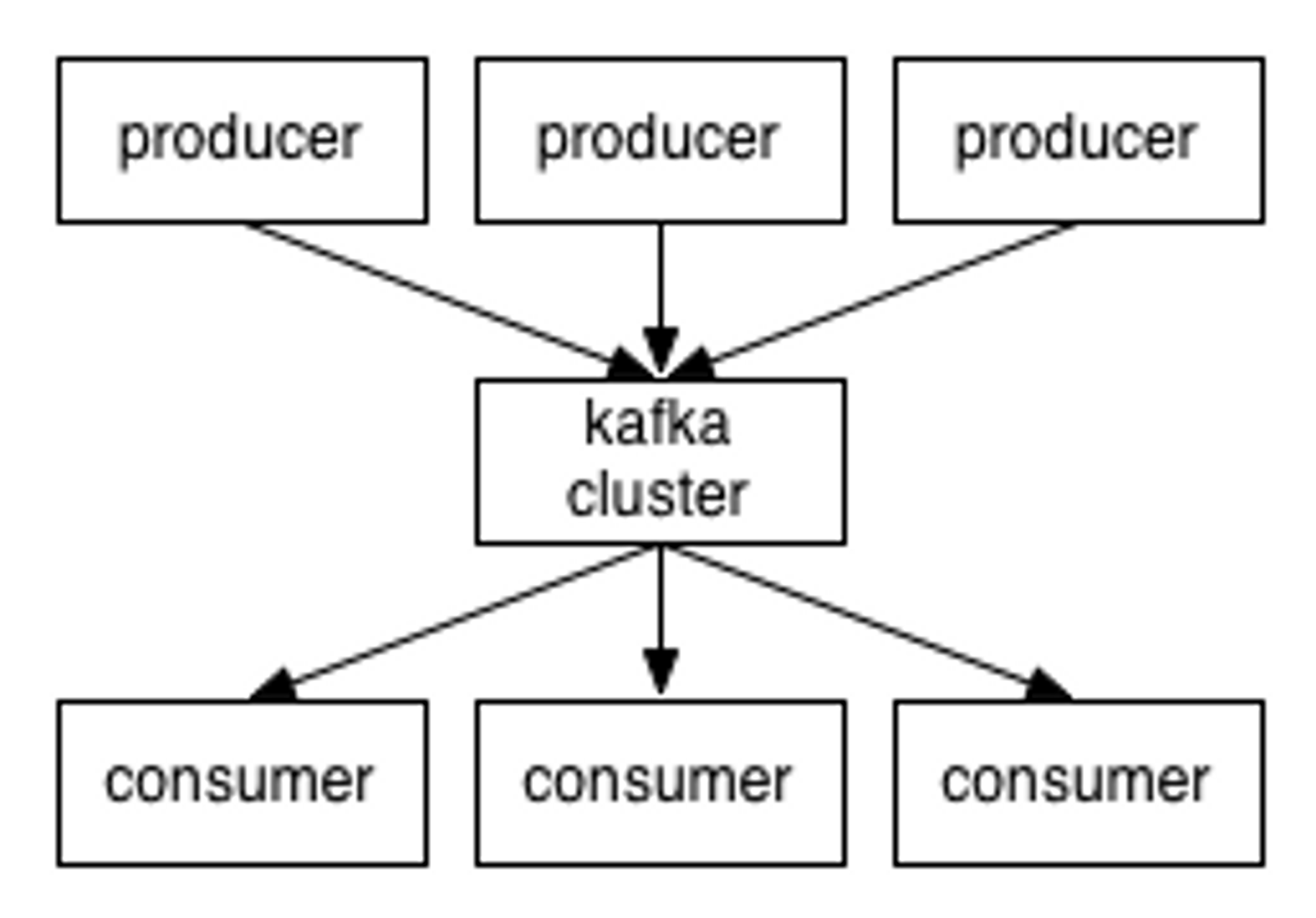
*kafka cluster: kafka 서버 (broker)로 이루어진 클러스터를 말한다.
broker: 메세지 중계 역할을 하는 kafka서버를 말한다.
*topic: kafka cluster에 메세지를 관리할 때, 기준이 되는 논리적 모델이다. 여러개를 생성할 수 있으며, 하나의 topic은 1개 이상의 partition으로 구성되어 있다.
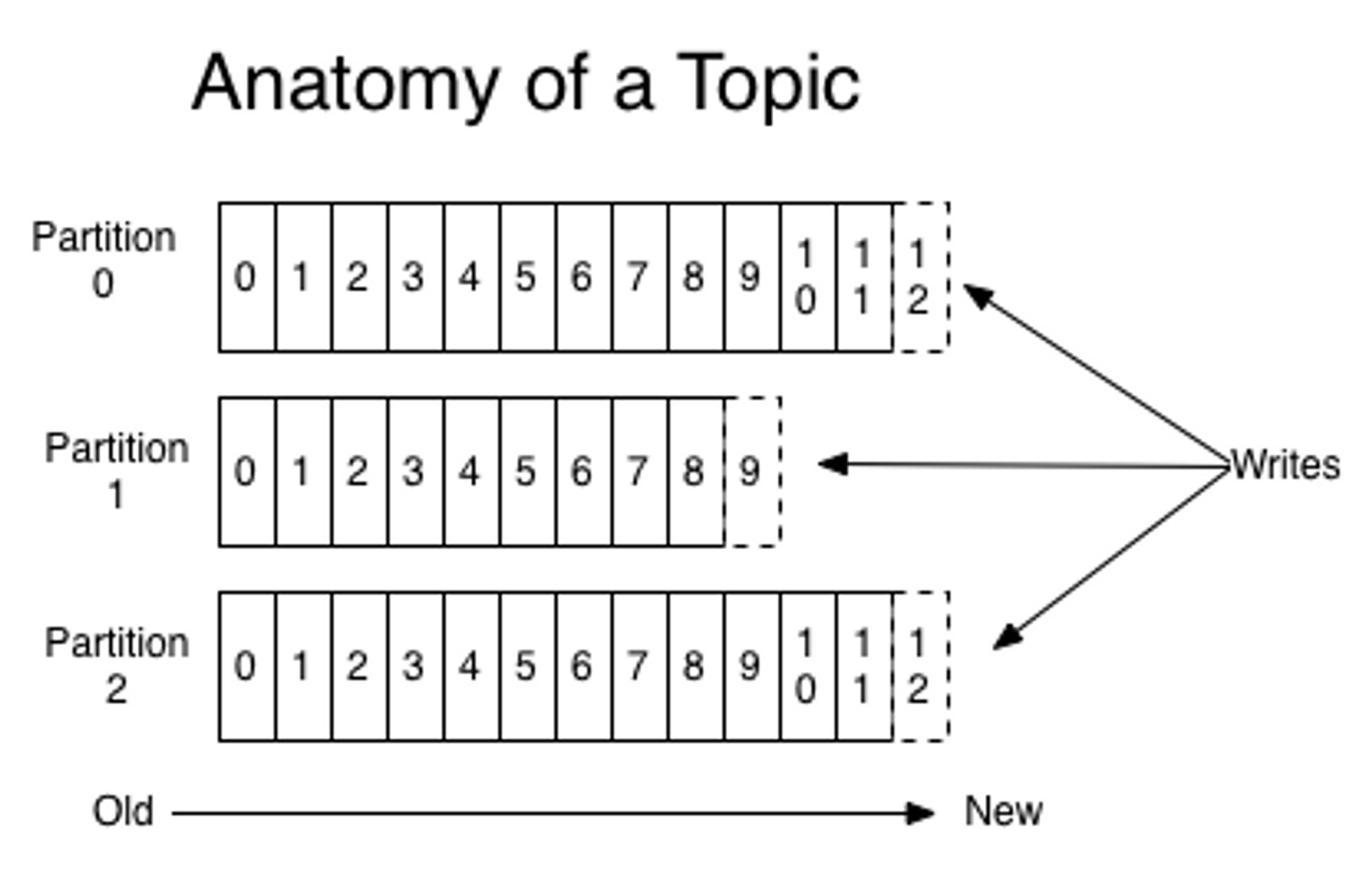
partition: 토픽에서 메세지를 분산 처리하는 단위이다. 토픽을 partition으로 나누어 나눈 만큼 분산 처리를 한다. kafka option에서 지정한 replica (replication factor)의 수만큼 partition이 broker들에게 복제된다.
leader & follower: kafka 에서는 복제된 partition들 중에서 하나의 leader가 선출된다. leader는 read, write 연산을 담당하며, follower들은 leader의 메세지를 복사한다. leader partition이 포함된 broker에서 장애가 발생하면 follower partition들 중 하나가 leader가 된다.
*consumer group - 상세 설명: consumer의 집합을 구성하는 단위이다. kafka에서는 consumer group 단위로 메세지를 처리하고, consumer group의 consumer 수만큼 파티션의 데이터를 분산처리하게 된다.
*offset - 상세 설명: consumer group들은 partition의 offset을 기준으로 데이터를 순차적으로 처리한다.
3.1.1. consumer group
여러개의 producer 들이 메세지를 전달하는 속도가 consumer가 메세지를 처리하는 속도보다 빠르면 하나의 consumer 만으로는 전달되는 메세지를 모두 처리할 수 없다.
따라서 consumer group을 통해 메세지를 처리한다.
consumer group은 같은 토픽의 여러개의 partition을 분담하여 처리하게 된다.
가령 partition의 수가 4개이고, consumer group의 consumer가 2개라면 각 consumer는 2개씩의 partition을 분담하여 메세지를 처리한다. 또한, partition의 수가 consumer group의 consumer 수보다 적다면 partition을 분담하지 못한 consumer는 idle이 된다.
3.1.2. offset
producer는 메세지를 순차적으로 전달하고 디스크에 순차적으로 저장한다. 따라서 저장된 메세지 뒤에 세로운 메세지를 붙이는 append 방식으로 write를 진행한다. 이 때 partition 들은 각 메세지의 순차적인 위치인 offset으로 구성된다.
따라서 offset은 partition 내에서 메세지의 위치를 표시하는 유니크한 숫자이다. consumer는 자신이 어디까지 메세지를 처리했는지 offset을 이용해서 관리한다.
4. zookeeper 란?
zookeeper는 분산 애플리케이션이 안정적으로 서비스될 수 있도록 각 애플리케이션의 구성 정보를 중앙 집중시키고, 네이밍, 동기화 등의 서비스를 지원한다.
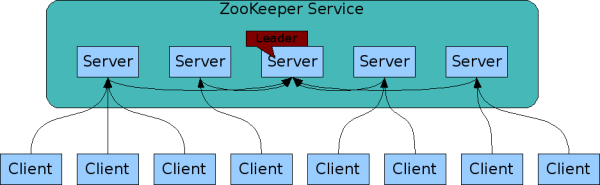
zookeeper 여러개를 하나의 클러스터로 구성하고, 각각의 zookeeper 서버는 클라이언트 애플리케이션과 커넥션을 유지하며, 상태 정보를 공유한다.
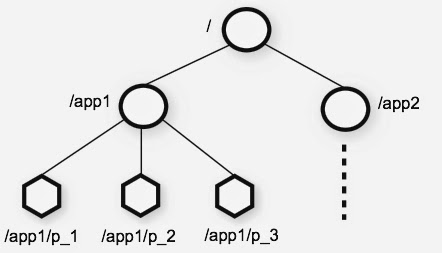
상태 정보는 zookeeper의 데이터 레지스터의 공유 계층 name space에 저장된다. 그리고 이 공간을 znode라고 부른다.
znode는 key-value 형태이며, 자식 노드를 가지고 있는 계층형 구조로 구성되어 있다.
zookeeper는 클러스터로 구성될 시 몇개의 서버가 다운되더라도 과반수 구조에 의해 서비스가 유지된다.
따라서 일반적으로 클러스터는 홀수개의 서버로 구성된다.
3대 구성 클러스터: 1대 down, 2대 up: 서비스가 유지된다. 2대 down, 1대 up: 서비스가 유지되지 않는다.